I remember a long time ago when CPUs still had only a single core and the chip manufacturers where racing for getting the highest Gigahertz. Then some technical limit was reached they shifted their philosophy to increasing the number of CPU cores. The unfortunate side-effect of this approach is that we developers need to adapt our code to make use of these multiple cores or else our CPU-intensive code will find a bottle neck in being only able to max out one core.

In a previous article I described how optimizations in genstrings2 (our Open Source replacement for genstrings) led to the re-implementation being upwards of 30 times faster than the original.
The reason of this was mostly grounded in some smart using of multiple GCD queues. In this blog post I shall explore how we can get DTCoreText to also make use of all available CPU cores.
Since its inception DTCoreText has seen two major shifts in architecture. The first in version 1.1 was to switch from using NSScanner to libxml2. The second was to simplify the synthesis of the mutable attributed string by having a node tree and only append whenever nodes are being closed, as opposed to all the time. This was version 1.2.
Consider this Instruments CPU time graph. The big purple plateau is DTCoreText parsing War and Peace HTML and creating an NSAttributedString for it. This is about the longest ePub document there is, if not the longest. So this is a perfect candidate to test the effectiveness of optimizations.
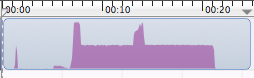
There are some things quite apparent in this chart. This is obviously a dual-core device (iPhone 5) and it maxes out one core fully. Then there are two spikes where a second core kicks in for a very short time.
A Tale of 2 GCD Queues
The reason for this comes from DTCoreText already using two queues for its work, one for running the parser and one for appending to the mutable attributed string.
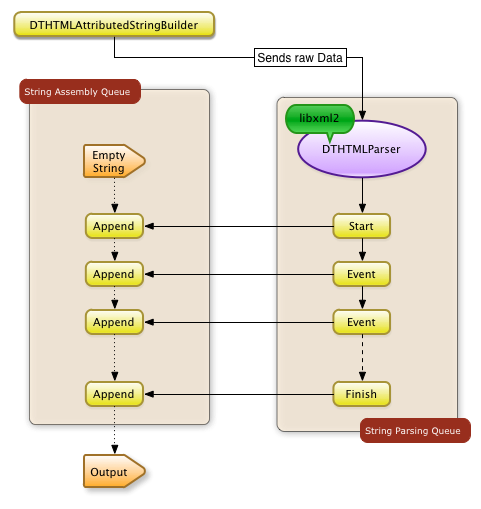
But these queues are only responsible for the left half of the CPU graph until the second spike. This right half is actually the building of the Core Text layout. The first 1 second spike is the actual parsing of the HTML data, after that the parsing queue is basically idle. Then for the remaining 6 seconds of the first phase the string assembly queue continues to execute the individual asynchronous blocks that where added in response to the DTHTMLParser delegate callbacks.
The second part, which we will not look at today, 8 seconds in duration, could also be halved if two cores would be used instead of one. Which is somewhat harder because as it is working presently we are manually typesetting the entire attributed string from beginning to end. Let’s make a note and revisit that some day as well.
Scotty, We Need More Queues!
At this point it becomes clear that we need to split off part of the work currently filling up the string assembly queue into a new queue. Here’s how the “Heaviest Stack Trace” looks like for this range

When I first saw this I thought to myself, “GCD is 50% overhead”. From this view in Instruments we can clearly see that _dispatch_call_block_and_release is doing quite a bit of work here. No clue how to optimize that, if you have any ideas let me know!
Next in the ranking of heaviest functions is our end-of-element callback from DTHTMLParser. Then there is the attributedString method of DTHTMLElement of which about half is DTHTMLElementText attributedString. So one idea is to split out the creating of the attributed substrings. In the following flow chart you can see the new design.
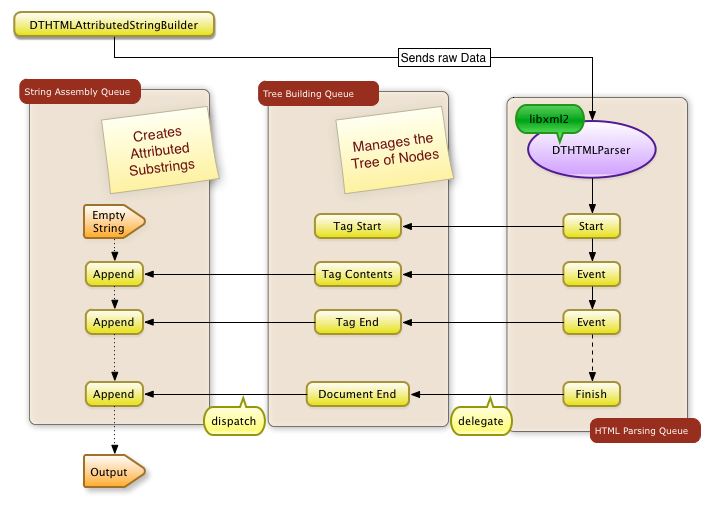
Even though it was a bit of a crap shot to determine where to best separate the functionality we now are getting a dramatically different profile:
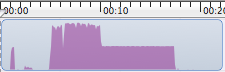
The left portion is visibly taller and shorter in time.
The usual question to ask in this scenario is if the existing functionality is still intact. Initially it looked like it, but the unit tests started to fail. I needed to add a bit of synchronization around several properties of DTHTMLElement and rearranged some code. It took a bit of tweaking but I eventually got the unit tests to pass again.
Now how much does that gain us?
Version 1.2: 2013-03-02 16:31:40.280 RTDemoApp[2503:907] DTCoreText created string from 3.2 MB in 5.68 ms with tree queue: 2013-03-02 16:33:18.813 RTDemoApp[2522:907] DTCoreText created string from 3.2 MB in 4.14 ms with function for start: 2013-03-02 17:23:21.762 RTDemoApp[2599:907] DTCoreText created string from 3.2 MB in 4.26 ms and function for end: 2013-03-02 17:34:01.104 RTDemoApp[2636:907] DTCoreText created string from 3.2 MB in 4.33 ms with fixed unit test: 2013-03-02 18:04:40.350 RTDemoApp[2801:907] DTCoreText created string from 3.2 MB in 4.11 ms release build: 3.8 ms versus 4.09 ms
As you can see I did some other experiments as well.
One idea was to replace the dispatched blocks with functions. But as the tests clearly demonstrated this was not worth the effort. You have to do some extra magic to reproduce the variable capturing functionality that blocks to automatically for us. But all this work makes it ever so slightly slower. Slower performance coupled with less readability of the code is a clear No Go.
The Verdict
Having multiple dispatch queues allows for a greater deal of concurrency while still working of individual tasks in a serial fashion. Obviously you have to parse through the HTML data from top to bottom, build the tree the same way and always append to the attributed string at the end. But that does not mean that the interleaved work units have to be forced to wait for each other.
The final result from our benchmarks have shown a 28% improvement in duration for creating an attributed string from our War&Peace test document. Granted this is not the halving of the duration that we where hoping for, but nevertheless it is a great start.
By having one serial queue per stream of tasks I have shown how you can improve usage of multiple CPU cores where available. As more and more iOS devices sport multiple CPU cores it is up to us developers to code our CPU-intensive code such that it can finish those tasks in the least amount of time.
![]()